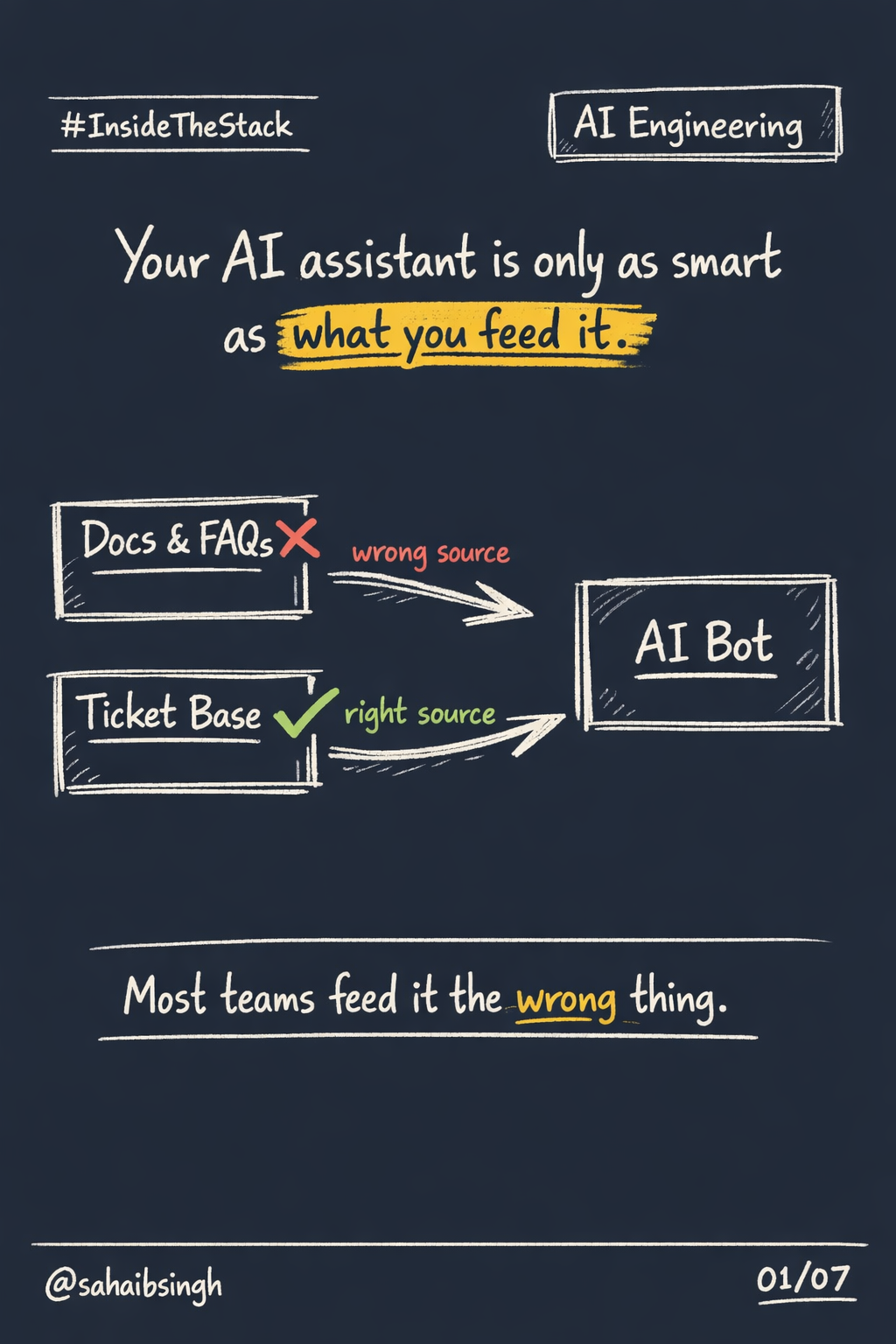
InsideTheStack Your Ticketing System Is a Knowledge Base. You're Just Not Using It. Most teams building AI assistants start in the wrong place. They open
InsideTheStack Convenience Is Deferred Complexity Why “easy now” becomes “hard later” Convenience feels fast. Complexity just waits.
InsideTheStack Observability Is Not Dashboards. It’s Reconstruction Reality It is reconstruction of reality Dashboards show you what you expected to
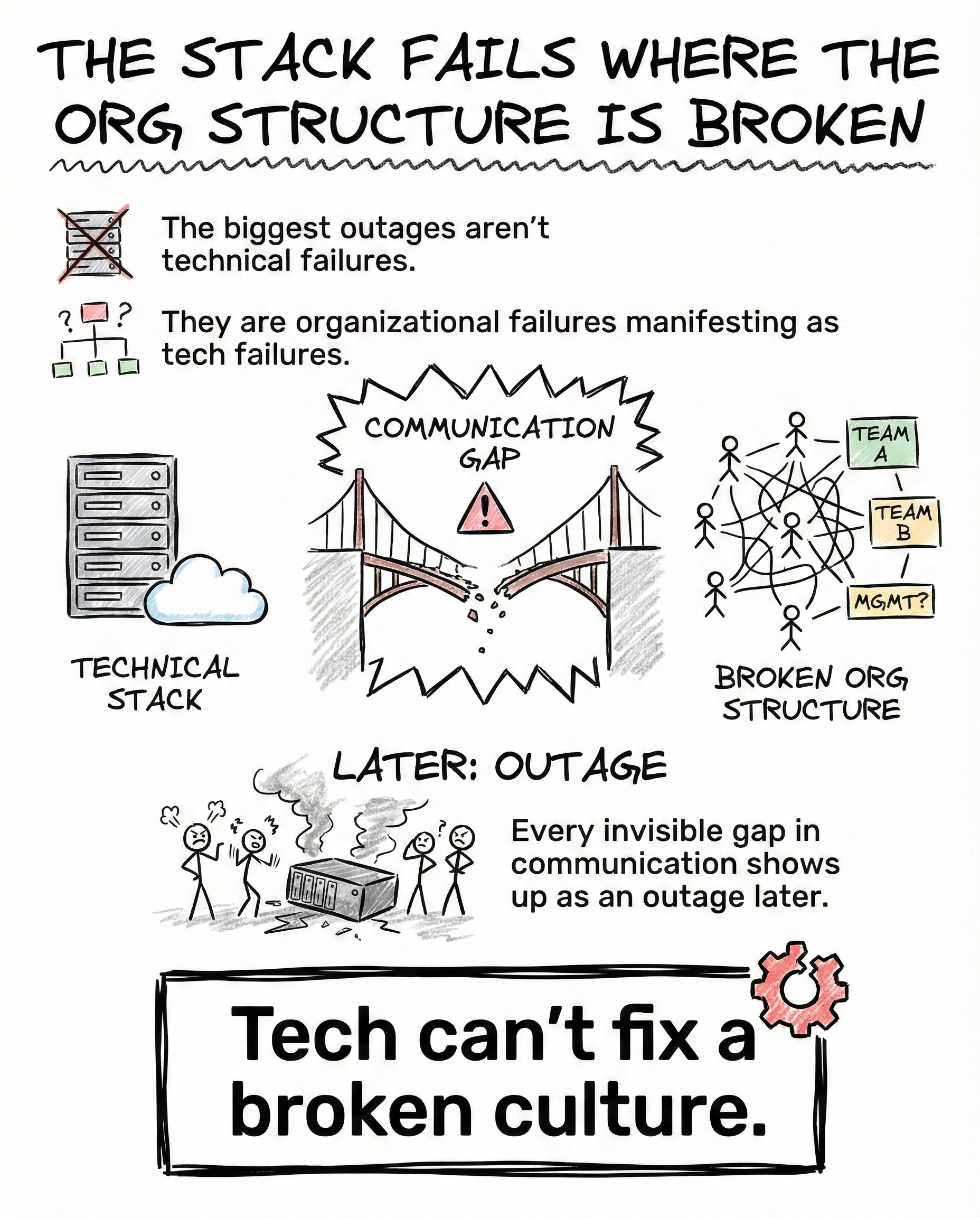
InsideTheStack The Stack Fails Where the Org Structure Is Broken Why the biggest outages are rarely technical The biggest outages are not
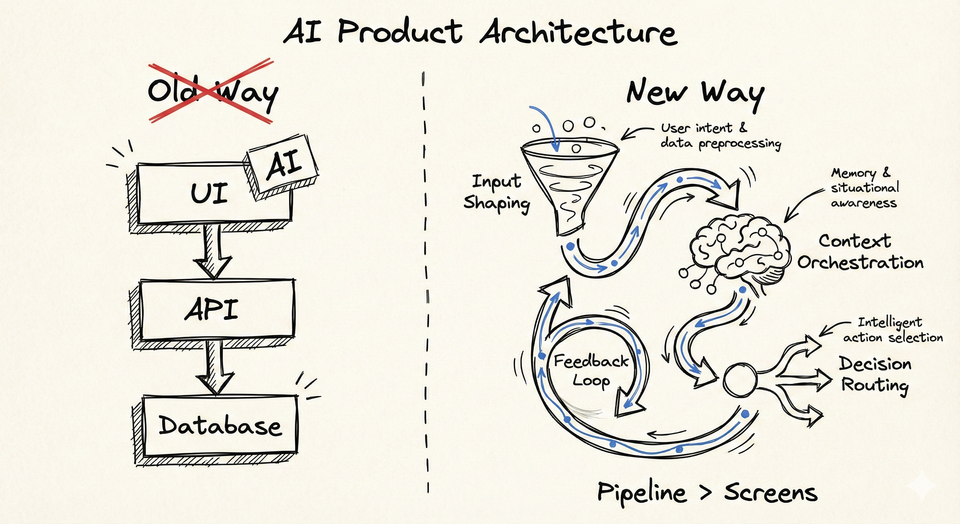
Notes & Trends Building for AI Is Not Adding AI It Is Rewiring Your Entire Product Architecture Most products today claim to
InsideTheStack Preventive Architecture For Small Teams Preventive Architecture for Small Teams How small teams avoid big failures without
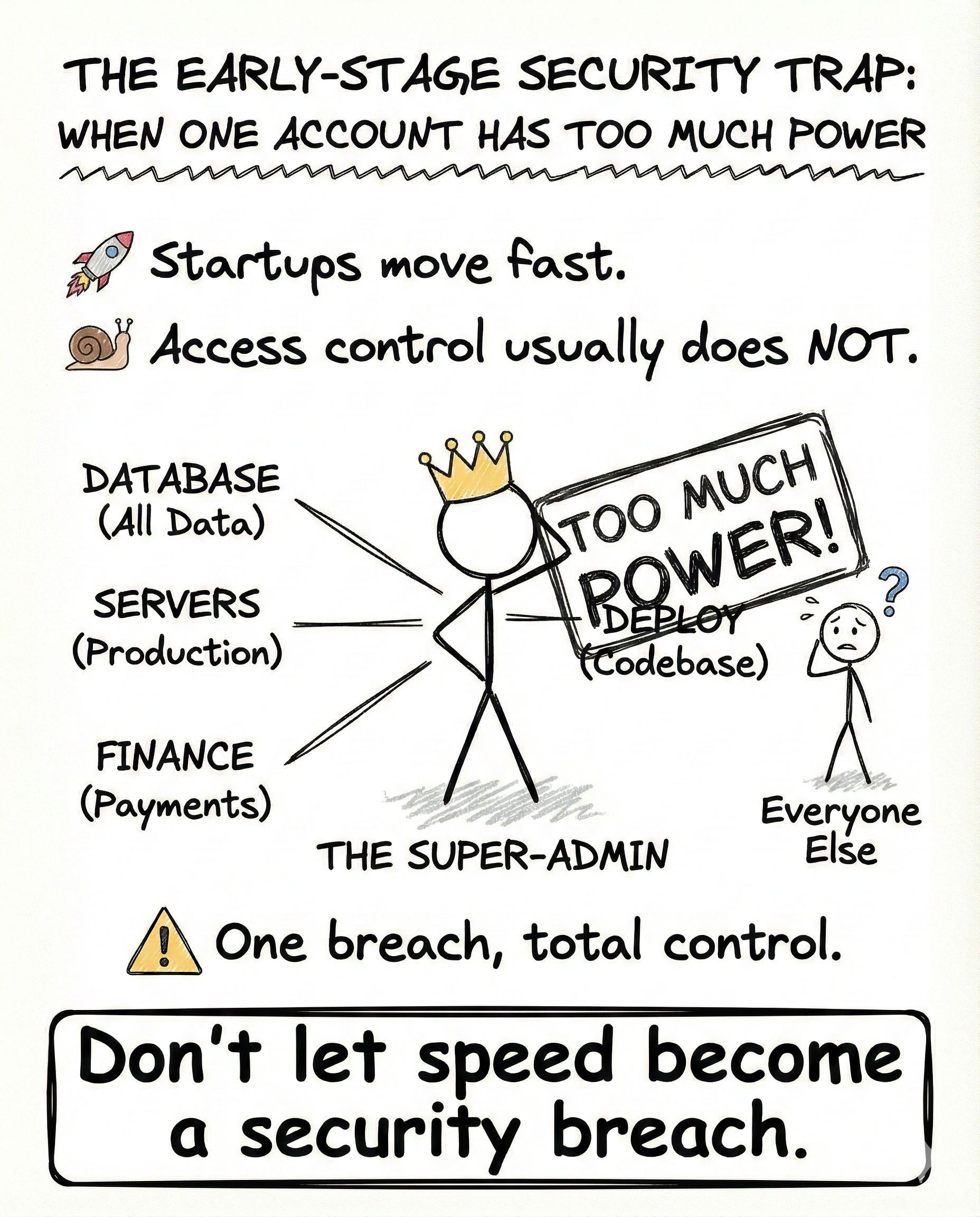
InsideTheStack Early-Stage Security Trap: Overpowered Access When one account has too much power Startups move fast. Access control
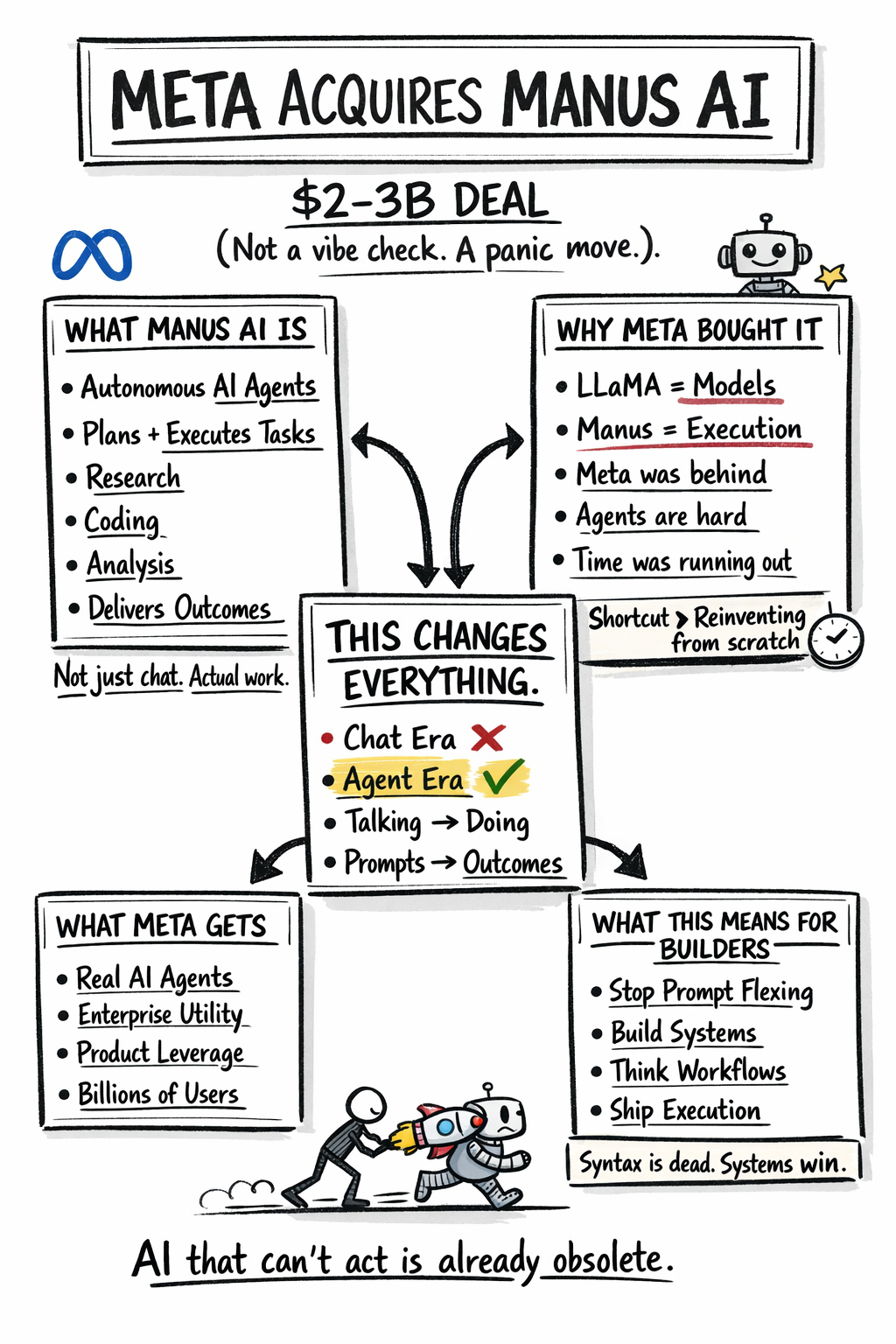
Notes & Trends Meta Acquires Manus AI: Why This Deal Actually Matters Meta just made one of its most important AI moves so far
Notes & Trends The Linkedin Apocalypse A recurring series on performance culture, fake wisdom, and why substance still
Notes & Trends India democratizes AI compute and launches AI research body Two moves from India: * A white paper to build AI on top
InsideTheStack The Coding Neutralisation Effect: Coding Won’t Be a Skill Soon The Coding Neutralisation Effect Coding won’t be a skill soon — engineering
InsideTheStack The Security Monitoring Stack Every Startup Should Have Even if you have zero security engineers You do not need advanced