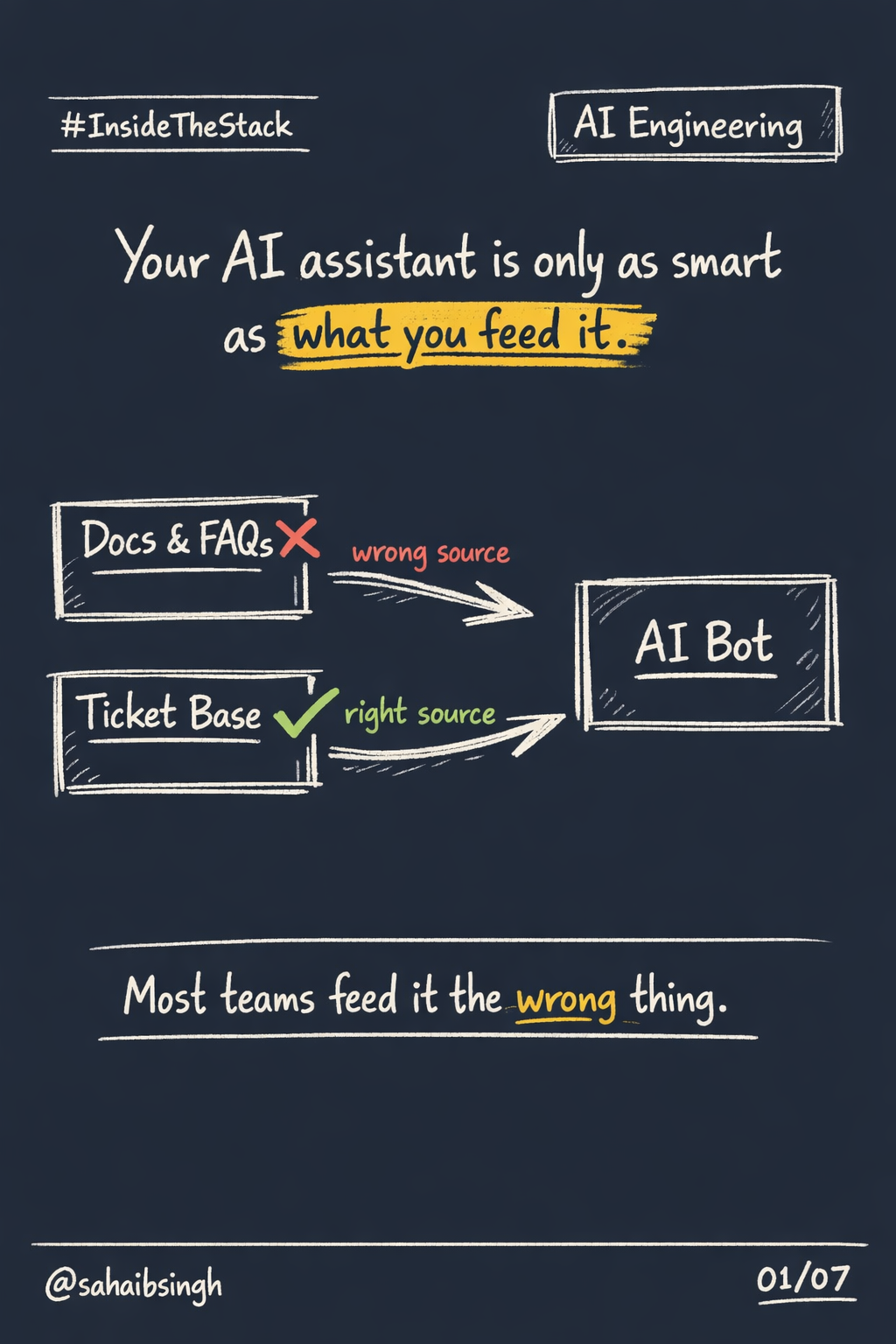
Convenience Is Deferred Complexity

Why “easy now” becomes “hard later”
Convenience feels fast.
Complexity just waits.
Managed services and abstractions reduce friction early, but they hide failure modes that only appear under real load, real traffic, and real stress.
If you do not understand how something fails, you do not control it.
Why this matters in real systems
Teams choose convenience for good reasons:
- faster iteration
- reduced operational burden
- fewer infrastructure decisions
- lower upfront cost
The trade is subtle.
Convenience swaps visibility for velocity.
That means:
- limits turn into secrets
- failure modes turn into surprises
- performance becomes unpredictable
This is not theory.
This is what happens when systems grow.

How convenience turns into deferred complexity
Convenience does not remove complexity.
It postpones it.
Hidden limits
Every managed service has:
- quotas
- soft limits
- throttling behavior
- retries and backoffs
When those thresholds are crossed, behavior changes. Often silently.
Example:
A storage service scales writes smoothly, then starts throttling without clear signals or alerts.
Nothing breaks outright.
Everything just slows down.
Failure abstraction
Managed services often swallow failure details.
They return:
- generic error codes
- wrapped exceptions
- partial success responses
Root cause disappears.
The system looks healthy.
It is not.
Dependency surface growth
Each managed component adds invisible dependencies:
- provider uptime
- SLA interpretation
- undocumented retry behavior
- internal scaling decisions
You did not design these dependencies.
You inherited them.

What changes at scale
At small scale:
- convenience routes around complexity
- failures are rare
- problems are shallow
At large scale:
- hidden limits bite
- retries amplify load
- errors cascade
Example:
A managed database throttles at a certain QPS.
The SDK retries automatically.
Those retries:
- increase latency
- saturate connections
- trigger upstream alarms
Now one limit becomes five problems.
This is emergent failure.
You did not design it.
But you must debug it.

What this looks like in production
Real incidents look like this:
- a managed queue silently dropping messages
- a cache evicting aggressively under memory pressure
- a load balancer failing open during spikes
- SDK retries amplifying a transient issue
Teams blame their code.
The code is usually fine.
The provider behavior under load is what changed.
These are not edge cases.
They are common.

The builder mindset that actually helps
From real debugging and system design work:
Know the hidden limits
Read the docs. Understand quotas before your system depends on them.
Simulate failure modes
Chaos testing is not luxury. It exposes assumptions that only appear under stress.
Instrument degradation paths
Measure retries, backoffs, slow responses, queue depth. Not just errors.
Watch behavior under load
A service that works at 10 percent load can collapse at 50 percent.
Convenience is not free.
It is a gamble.

A managed database example
A team chose a managed database to move fast.
Early results:
- instant provisioning
- no infrastructure work
- automated backups
In production:
- latency climbed as connections saturated
- internal throttling kicked in without warnings
- SDK retries caused a 5x increase in request time
Their application code did not change.
The behavior of the managed service did.
That is deferred complexity arriving on schedule.

The real takeaway
Managed services are powerful.
They are not dangerous by default.
They become dangerous when you treat them as magic.
Convenience is fine when paired with understanding.
Without it, you are borrowing speed against future outages.
Closing
This post is part of InsideTheStack, focused on engineering realities that prepare you for production, not just demos.
Follow along for more.
#InsideTheStack #SystemDesign #ManagedServices