Databricks + Databrain Practical Playbook

A practical playbook for real data workflows
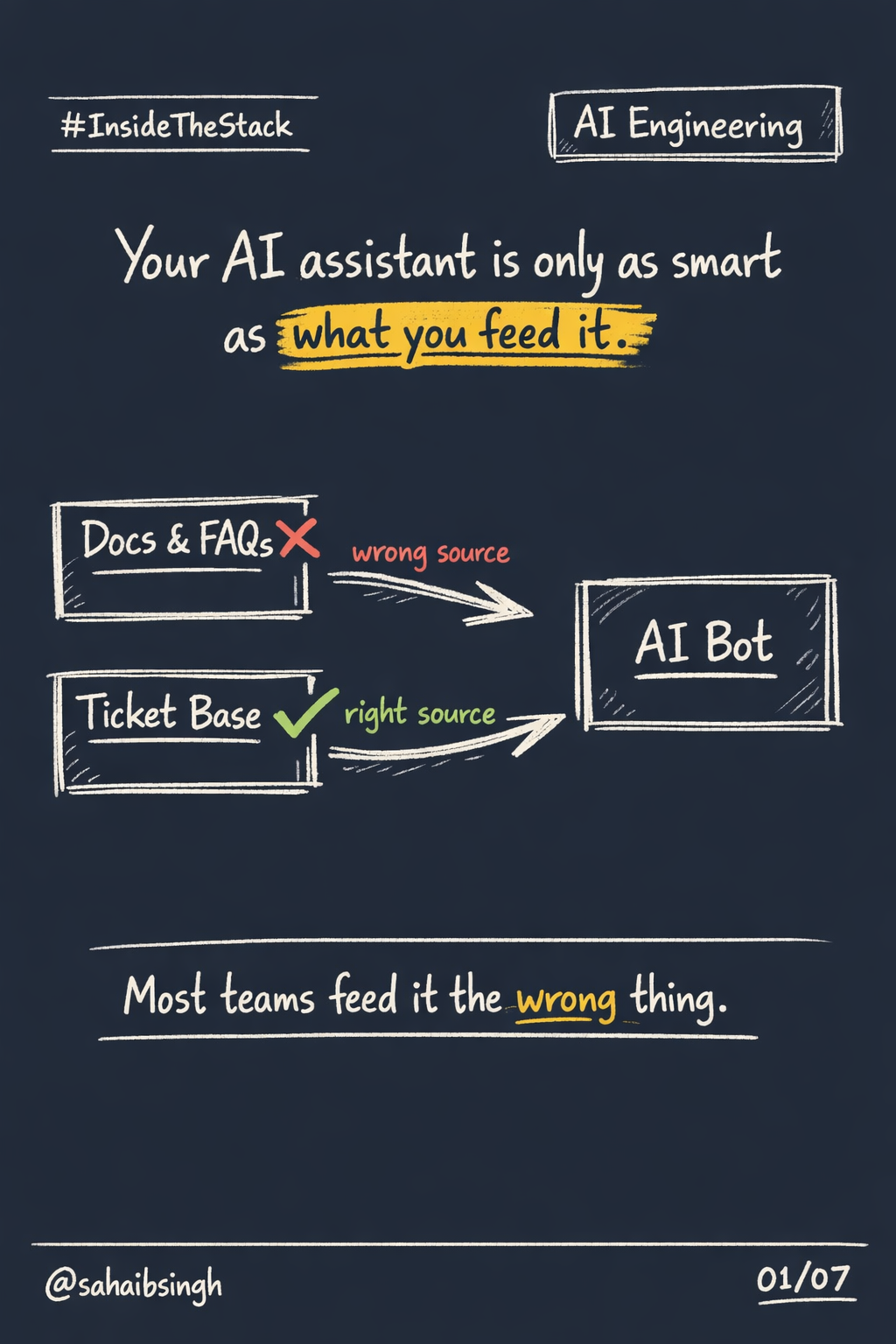
Most people think data platforms require specialists everywhere.
They do not.
What they require is clear structure, predictable jobs, and systems that do not fight you as they grow.
That is where Databricks combined with Databrain actually shines.
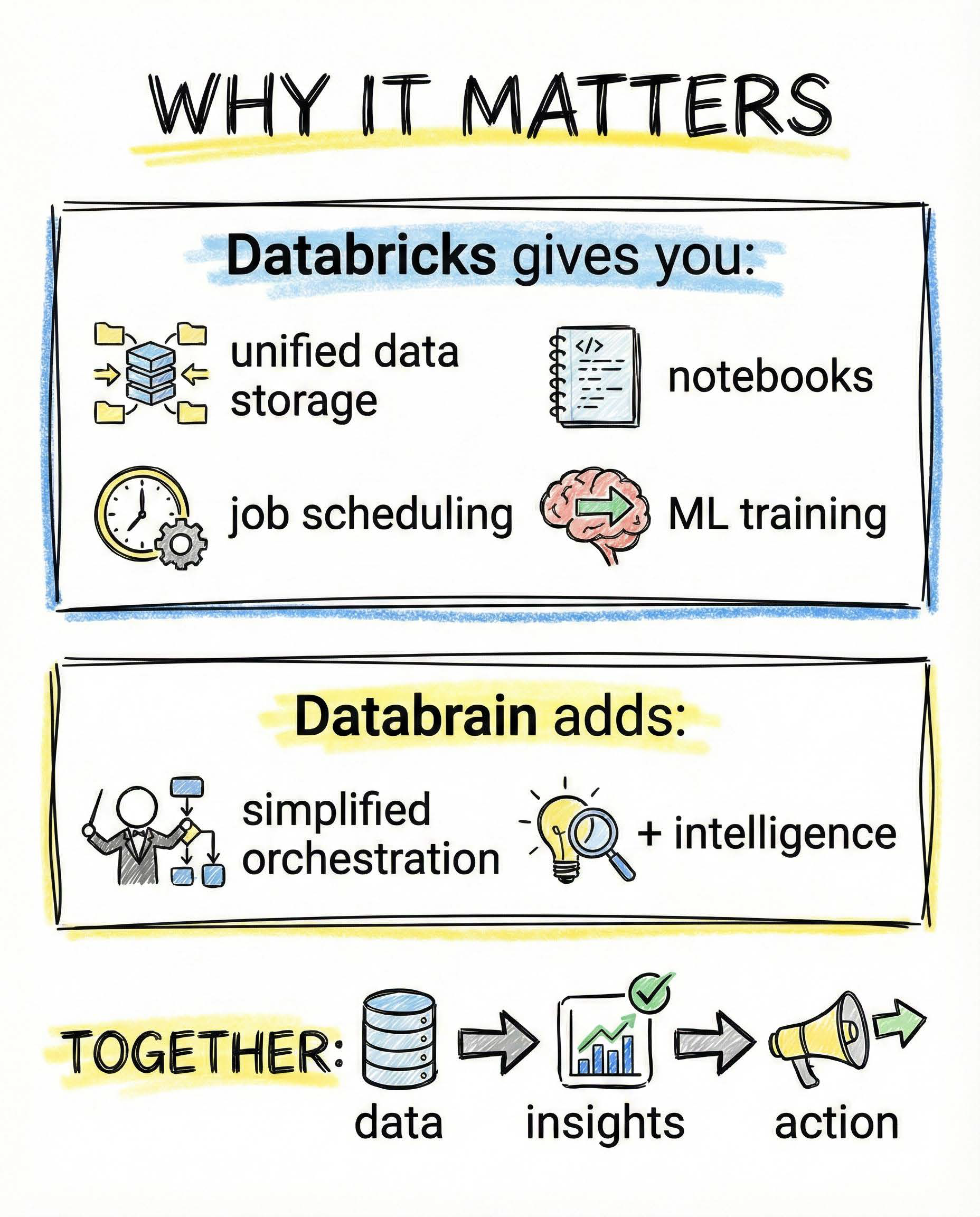
Why this setup matters
Databricks gives you the core building blocks:
- unified data storage
- notebooks for transformation and analysis
- job scheduling
- ML training and experimentation
Databrain adds a missing layer:
simplified orchestration, validation, and intelligence on top of those workflows.
Together, the pipeline becomes clear:
data flows in, gets shaped, validated, and turns into something usable.
Data to insights to action.
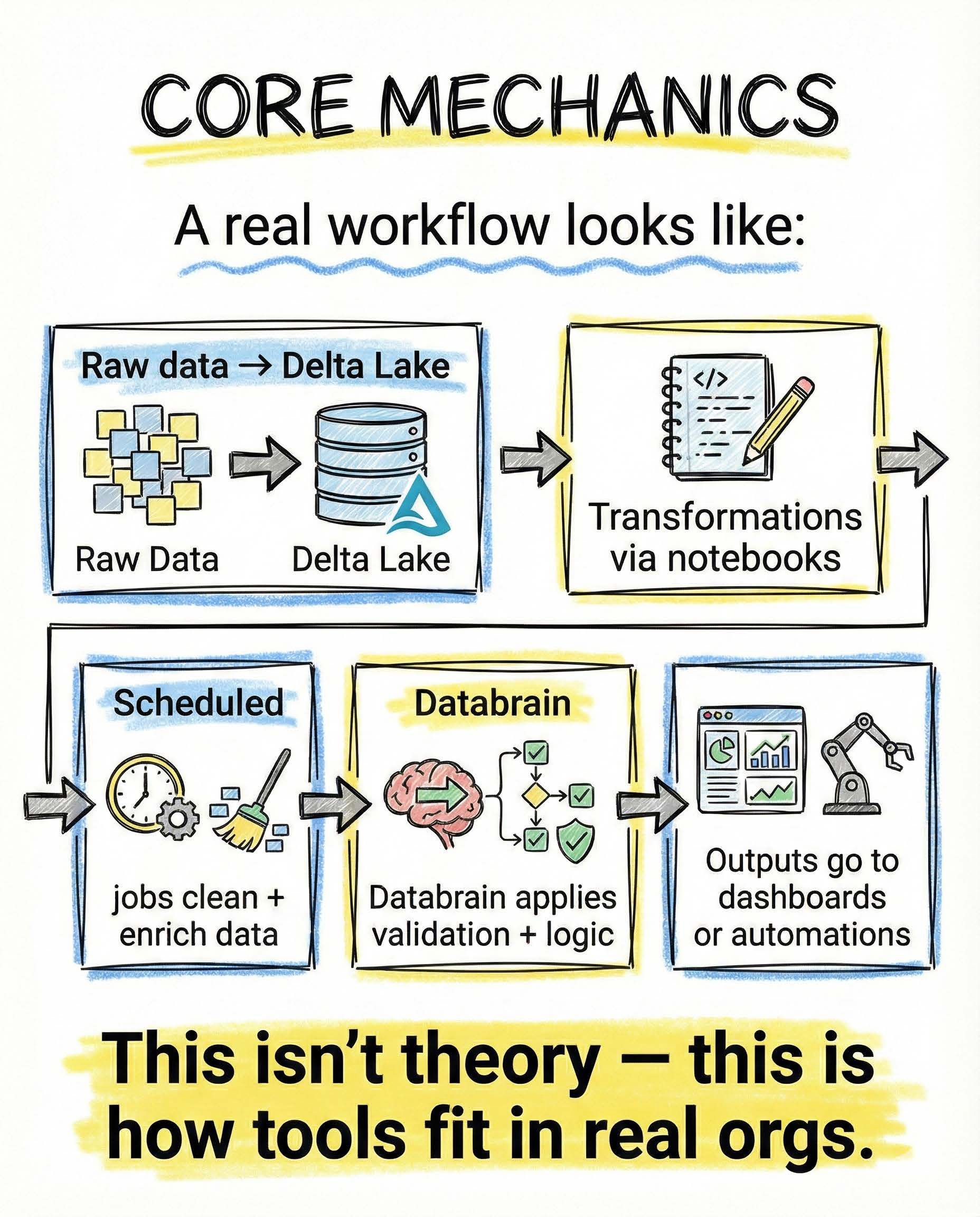
What a real workflow looks like
Forget diagrams that never survive contact with reality.
A practical setup looks like this:
- raw data lands in Delta Lake
- transformations happen through notebooks
- scheduled jobs clean and enrich data
- Databrain applies validation and business logic
- outputs feed dashboards, alerts, or automations
This is not theory.
This is how data platforms actually run inside real organizations.
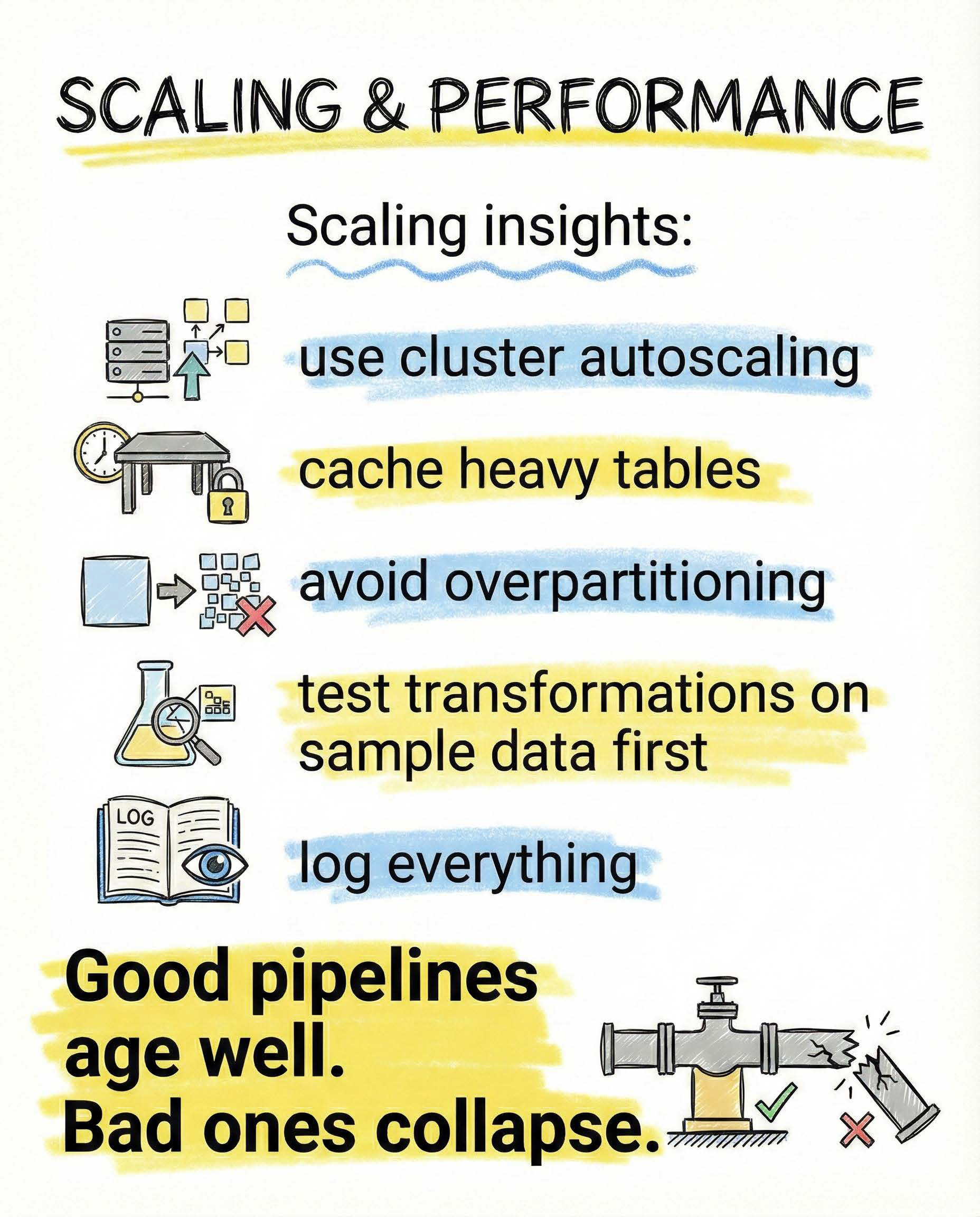
How pipelines scale or collapse
Pipelines do not fail because of volume.
They fail because of neglect.
What keeps them healthy:
- cluster autoscaling instead of fixed capacity
- caching heavy or frequently reused tables
- avoiding overpartitioning that kills performance
- testing transformations on sample data first
- logging everything that feels important
Good pipelines age quietly.
Bad pipelines fail loudly and often.
Lessons I learned using Databricks
Databricks rewards clarity, not cleverness.
The rules that held up over time:
- do not over-engineer pipelines early
- treat documentation as part of the pipeline
- keep transformations modular and testable
- build quality checks before users complain
- think in terms of jobs, not tables
When pipelines are easy to reason about, they are easy to maintain.
The real takeaway
Databricks plus Databrain is not about being a data specialist.
It is about building systems that can evolve without constant heroics.
Simple. Observable. Intentional.
That is what real data work looks like.

Closing
This post is part of InsideTheStack, focused on practical data engineering insights that survive real usage.
Follow along for more.
#InsideTheStack #DataEngineering #Databricks