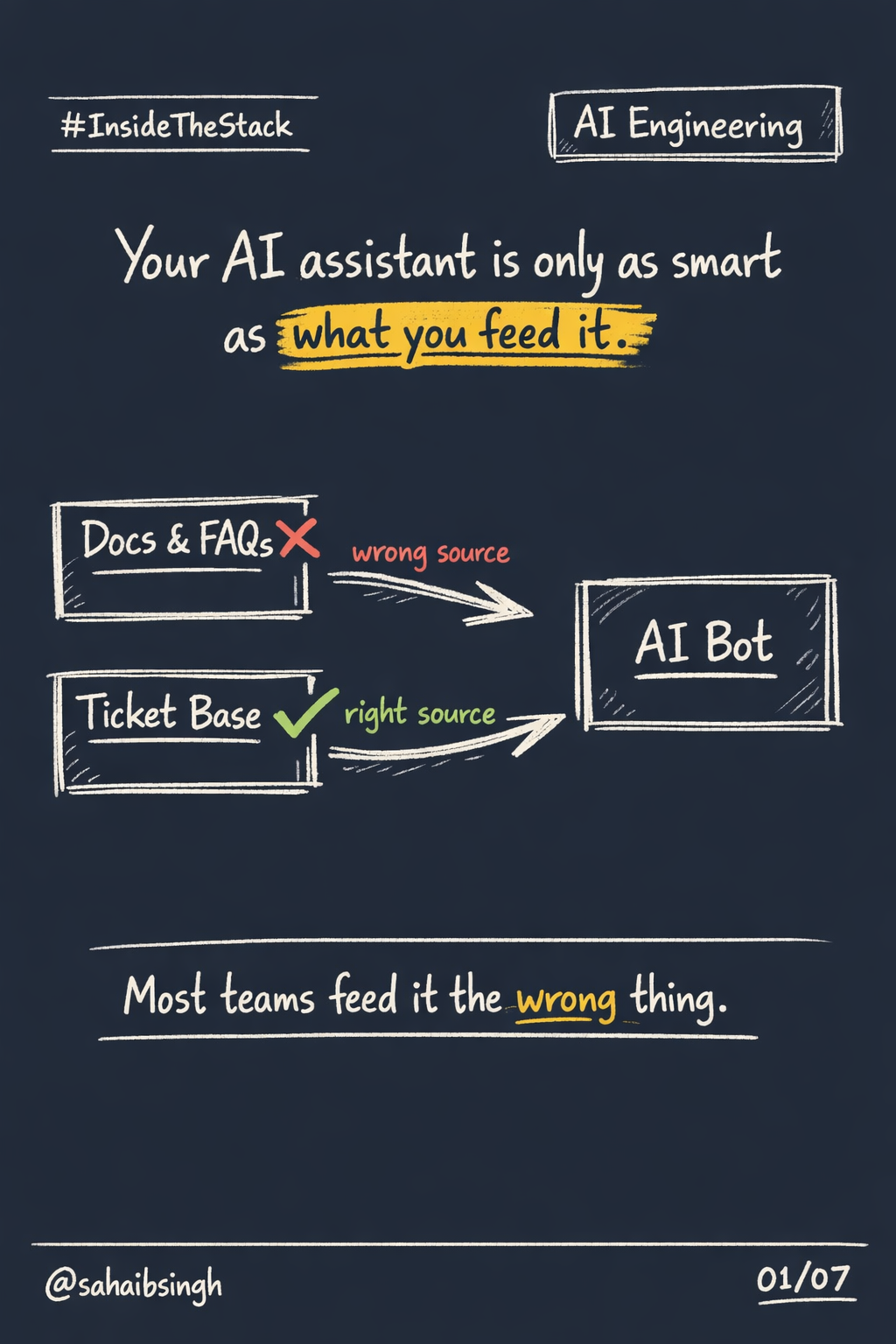
How Tokenization Actually Works

The hidden layer behind every LLM
Most people talk about models, parameters, prompts, context windows.
Almost nobody talks about tokenization.
That’s a mistake.
Tokenization is the first irreversible transformation your input goes through before a model “thinks”. If you don’t understand this layer, you are flying blind no matter how advanced your prompts look.
This post exists to fix that.
The visuals above already explain the shape of the idea. This blog fills in the mental model behind them.
Why tokenization matters more than you think
LLMs do not read text.
They read tokens.
Everything downstream depends on how your input is split before it ever reaches attention layers.
Tokenization directly affects:
- Cost You pay per token, not per word. Two prompts that look identical to you can be priced very differently.
- Response speed More tokens means more compute. That is not negotiable.
- Accuracy If a concept is split poorly, the model’s internal representation becomes noisy.
- Code understanding Symbols, indentation, operators, and variable names tokenize very differently from natural language.
- Multilingual performance English-heavy tokenizers punish non-English languages with higher token counts and worse compression.
This layer is boring to most people.
It is foundational to everything that follows.

What tokenization actually is
Tokenization is not splitting by words.
It is statistical compression.
Modern models use subword tokenization techniques trained on massive corpora. The goal is simple: represent text as efficiently as possible while preserving meaning.
Common approaches include:
- Byte Pair Encoding (BPE)Iteratively merges frequent character sequences into tokens.
- SentencePieceOperates directly on raw text, including whitespace and punctuation.
- Unigram modelsChooses the most probable tokenization among many possible segmentations.
That’s why a word like:
authenticationcan become:
auth | ent | icationThis is not random.
Each split exists because those fragments appear frequently across the training data.
The side effect is critical:
token boundaries influence how the model understands relationships between concepts.

Token count is a performance lever
Every extra token has consequences.
Token count impacts:
- Prompt cost
- Latency
- Memory usage
- Context window pressure
This is why two models with similar parameter counts can behave very differently in real workloads.
Models with more efficient tokenizers can:
- Fit more logic into the same context window
- Process code more predictably
- Handle long conversations with less degradation
This is one reason some newer models punch above their weight in coding and technical tasks. They waste fewer tokens on structure and syntax.
Efficiency here compounds.

Why builders should care deeply
If you build with LLMs and ignore tokenization, you will eventually hit confusing failures.
Understanding tokenization explains:
- Why a prompt suddenly stops working after a small edit
- Why numbers tokenize in unexpected ways
- Why JSON sometimes bloats token counts
- Why the same instruction behaves differently across languages
- Why some models feel “cleaner” for code than others
This is not theory.
This is operational knowledge.
Most AI users never learn this layer because the tooling abstracts it away. Builders cannot afford that luxury.

The uncomfortable truth
Prompt engineering without understanding tokenization is cargo cult behavior.
You can copy prompts.
You can tweak wording.
You can chase vibe-based improvements.
But until you understand how your input is actually segmented and priced, you are optimizing blindly.
Tokenization is not exciting.
It is not viral.
It is not aesthetic.
It is the hidden layer that decides whether everything else works.
Closing
This post is part of InsideTheStack, where the focus is not hype, not surface-level tips, but the mechanics that actually matter.
If you want to build AI systems that scale, behave predictably, and make economic sense, this is the layer you stop ignoring.
Follow along for more.
#InsideTheStack #Tokenization #LLM