KV Cache: Why Models Become Fast

The hidden mechanism that makes modern LLMs feel instant
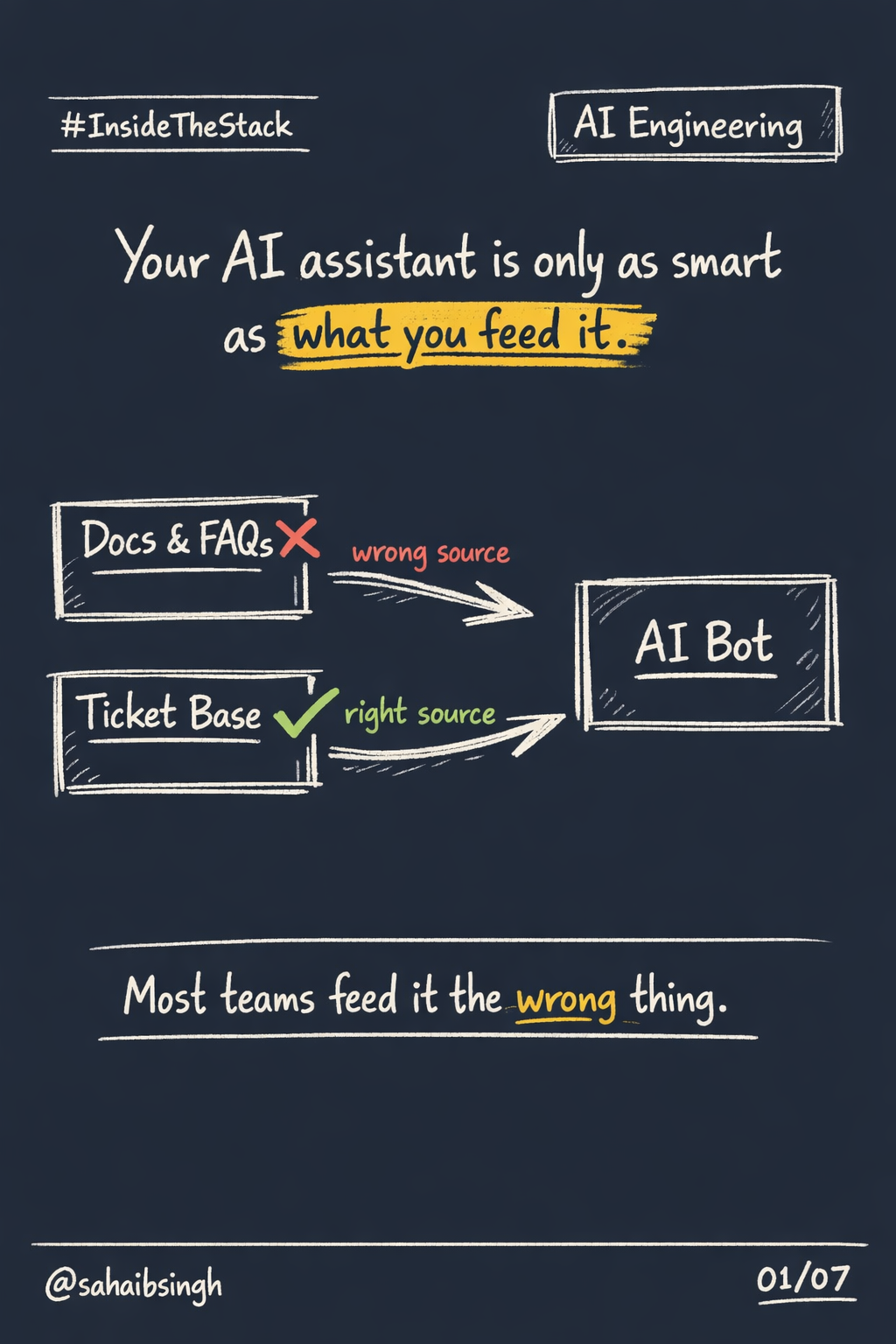
Most people think LLM speed comes from bigger GPUs or better models.
That’s only half the truth.
The real reason ChatGPT feels responsive is KV cache.
Without it, every response would feel like AI from 2020.
The slides above show the idea visually. This post explains what’s actually happening under the hood.
Why KV cache matters
Transformers are expensive because attention is expensive.
Naively, every new token would require recomputing attention over the entire past sequence.
KV cache fixes that.
Instead of repeating work, the model reuses previously computed attention state.
That single optimization changes everything about latency, cost, and scale.

What KV cache actually stores
For every generated token, the model computes and stores:
- Keys (K)
- Values (V)
These are not raw text.
They are compressed numerical representations of everything the model has seen so far.
Think of them as frozen memory.
When the next token is generated, the model attends only to this stored memory instead of recomputing attention from scratch.
Queries are new.
Keys and Values are reused.
That asymmetry is the entire trick.

Why models suddenly feel fast
KV cache enables:
- faster token-by-token streaming
- stable performance on long prompts
- lower GPU utilization per request
- dramatically cheaper inference
This is why modern systems can handle 200k+ context windows without collapsing under compute costs.
Without KV cache, long-context models would be economically impossible.

What builders need to internalize
Understanding KV cache helps you make better decisions around:
- model selection
- batch sizing and concurrency
- GPU memory planning
- deployment architecture
It also explains why:
- first tokens are slower than later ones
- long conversations stay responsive
- some models feel instant while others lag
This is not magic.
It is engineering.

The real takeaway
KV cache is not an optional optimization.
It is the reason transformer-based systems scale at all.
If you want AI systems that feel fast, cheap, and production-ready, you need to understand this layer.
Everything else is surface-level tuning.
Closing
This is part of InsideTheStack, where the goal is to explain what actually makes AI systems work, not what sounds impressive.
Follow along for more.
#InsideTheStack #LLM #KVCache