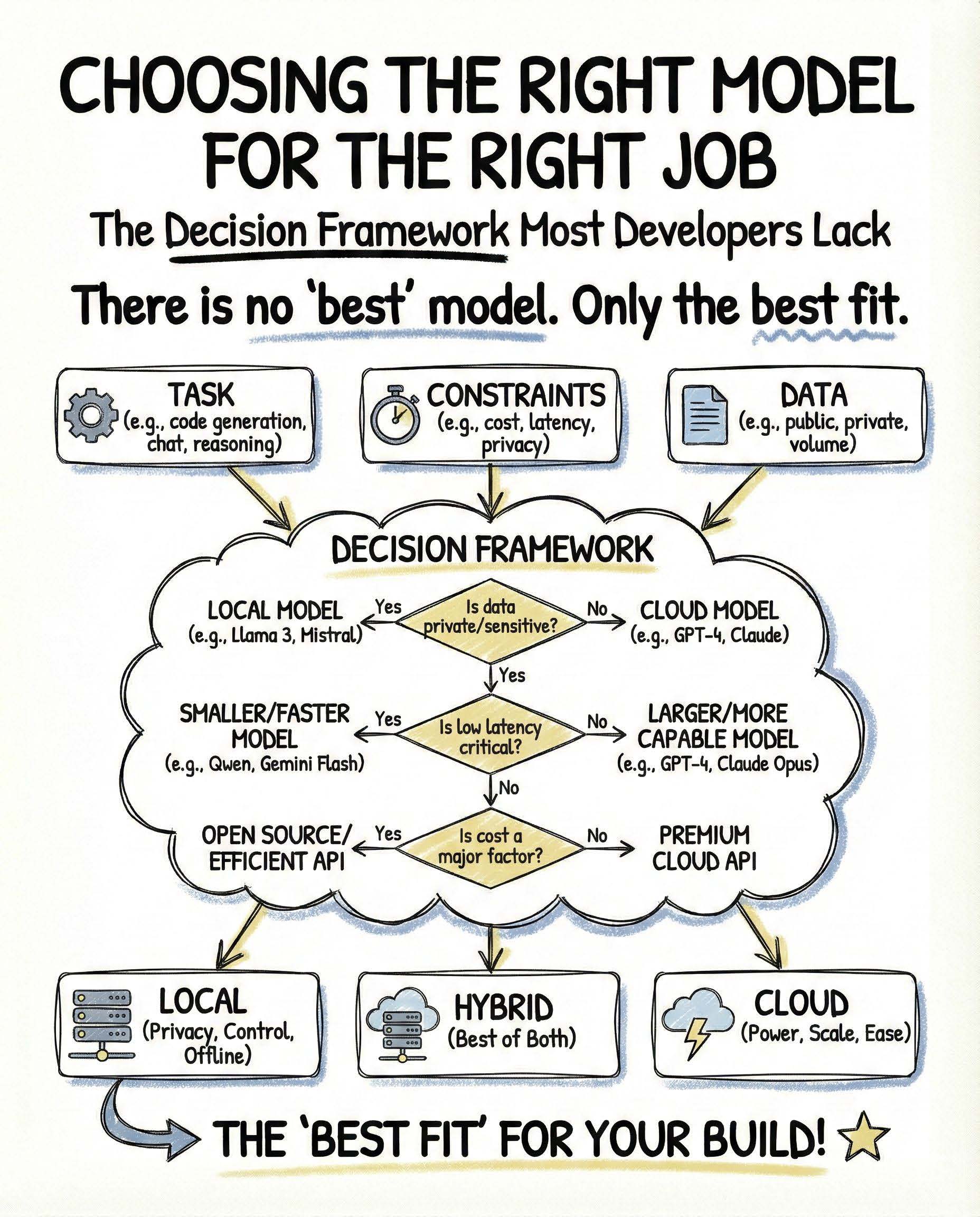
InsideTheStack Choosing the Right Model for the Right Job The decision framework most developers never build The idea of a “best
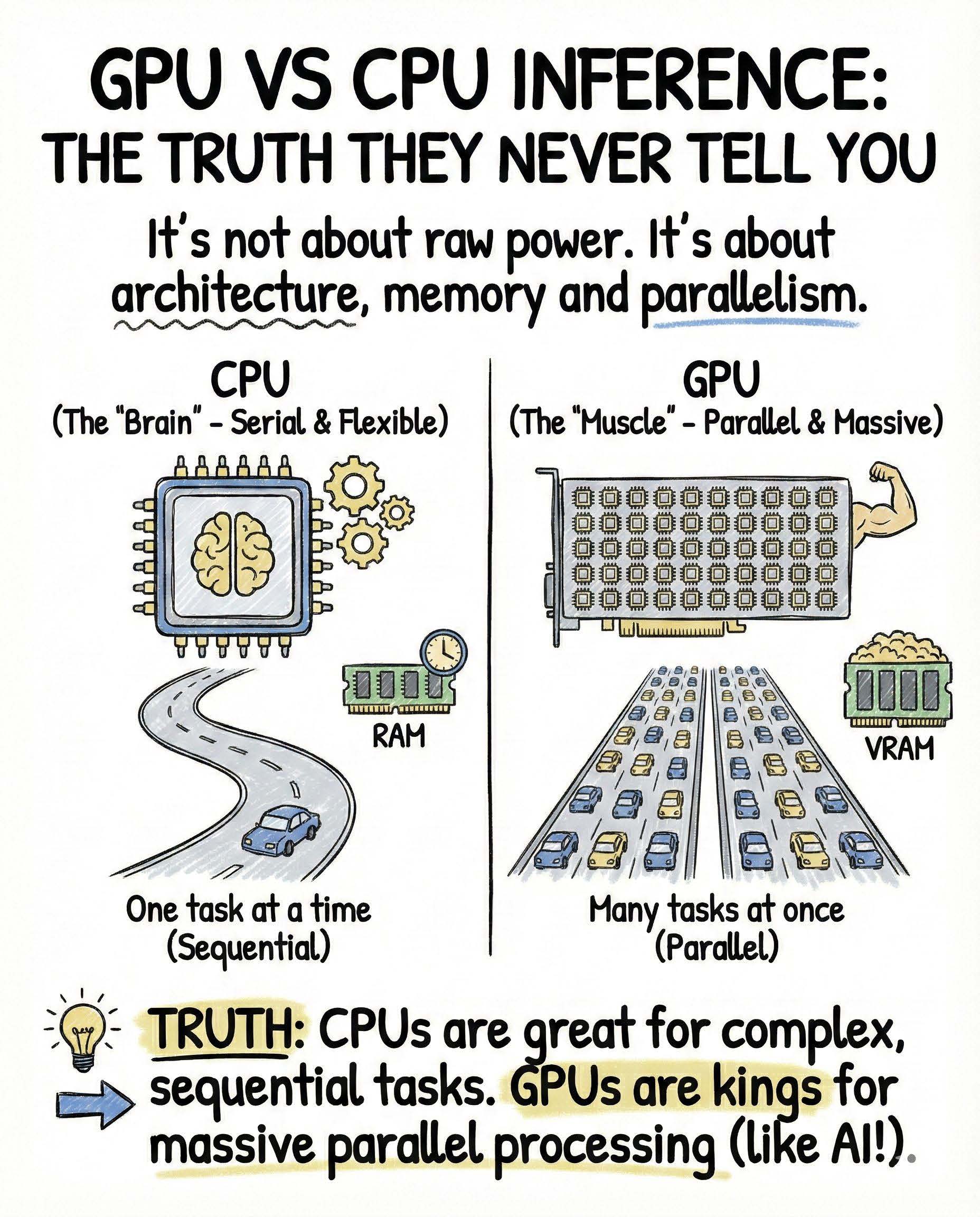
InsideTheStack GPU vs CPU Inference: Real Truths The real truths most people never tell you This debate is usually
InsideTheStack RAG That Actually Works And why 90 percent of people implement it wrong Most RAG systems
InsideTheStack Coding Models: Qwen2.5 vs GPT vs Claude Why Claude 4.5 changes the entire game For years, coding models
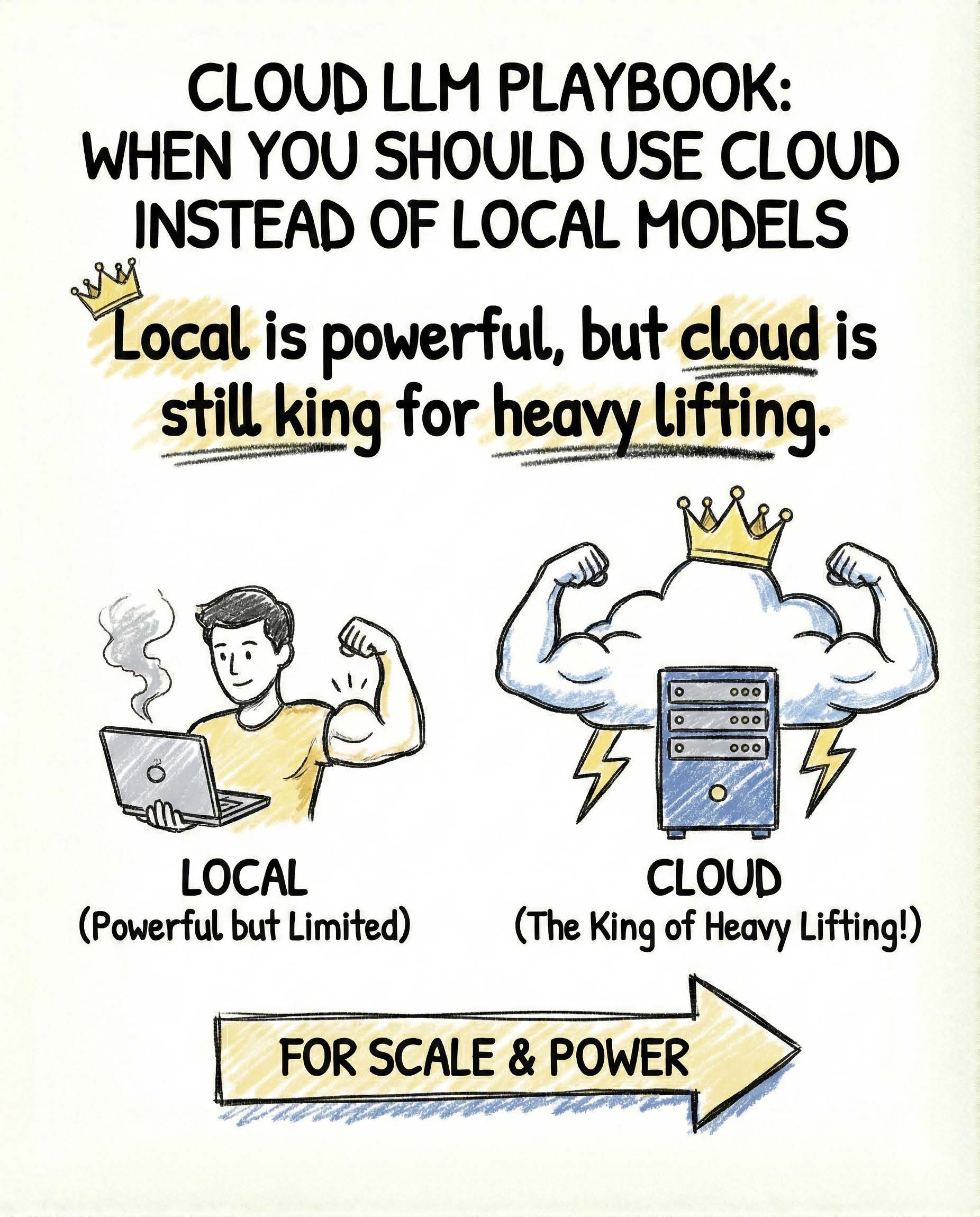
InsideTheStack Cloud LLM Playbook (OpenRouter, Cost vs Latency) When you should use cloud instead of local models Local models are
InsideTheStack KV Cache: Why Models Become Fast The hidden mechanism that makes modern LLMs feel instant Most people think
InsideTheStack How Tokenization Actually Works The hidden layer behind every LLM Most people talk about models, parameters,