The Stack Fails Where the Org Structure Is Broken
Why the biggest outages are rarely technical
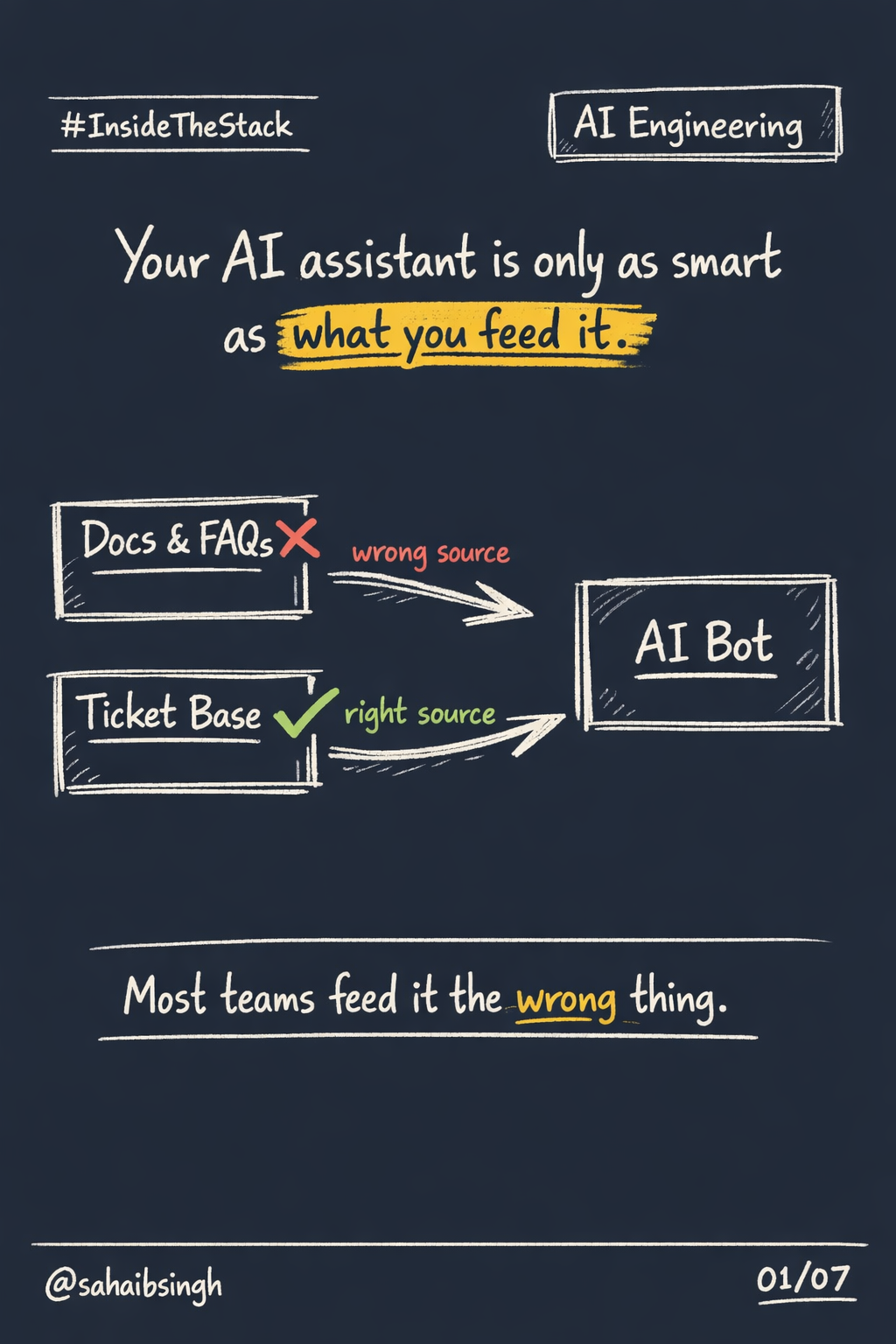
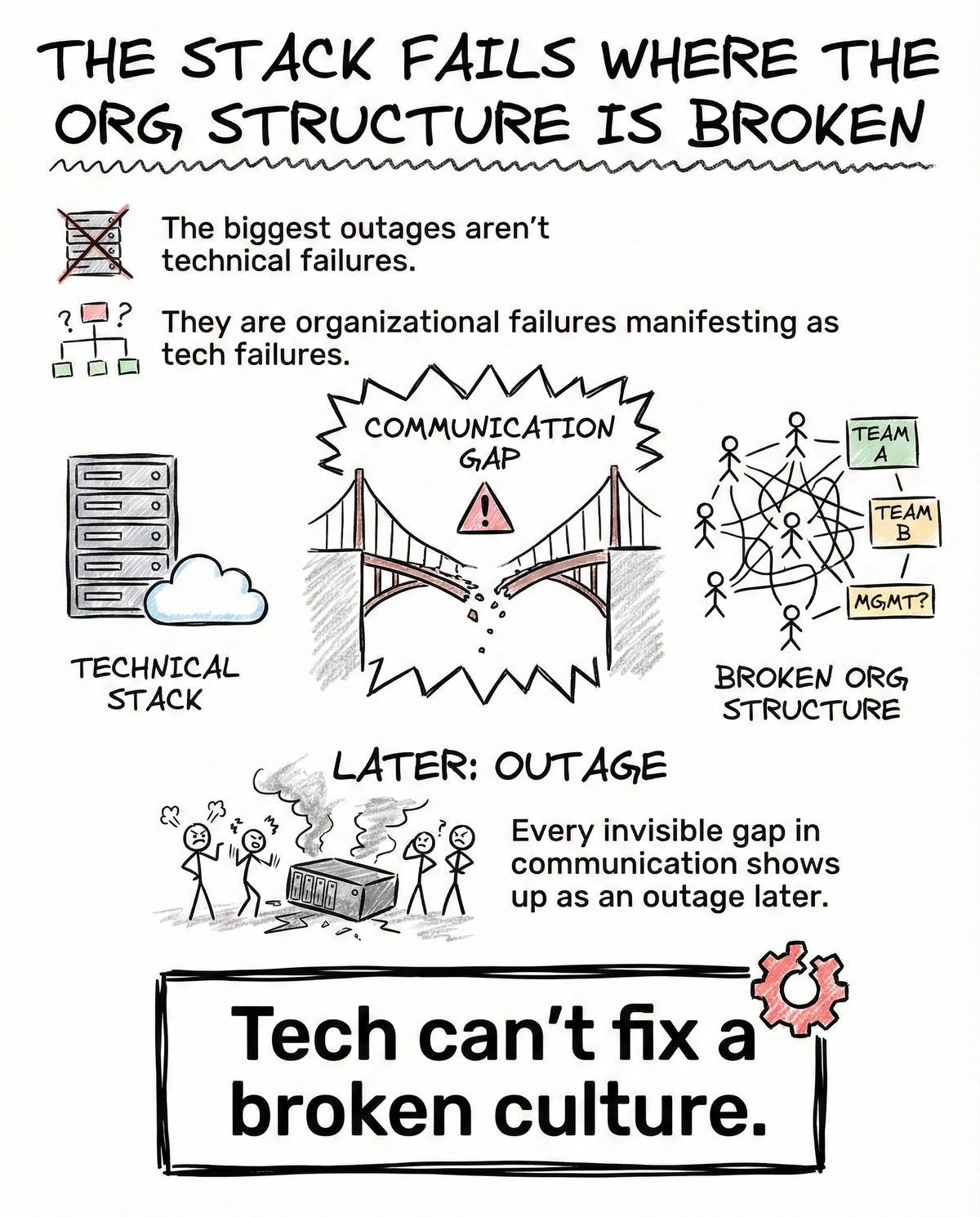
The biggest outages are not caused by bad code.
They are caused by invisible gaps in communication that eventually surface as technical failures.
Every time teams stop talking clearly, the system keeps a receipt.
It just redeems it later, in production.
Why this matters more than any framework choice
Modern systems are distributed.
And distributed systems mirror how people work together.
Architecture today is tightly coupled to:
- who talks to whom
- who owns what
- who is responsible when something breaks
When communication is fragmented, failures are not random.
They are delayed.
Outages are predictable if you know where teams do not align.
Conway’s Law is not theory, it’s a warning
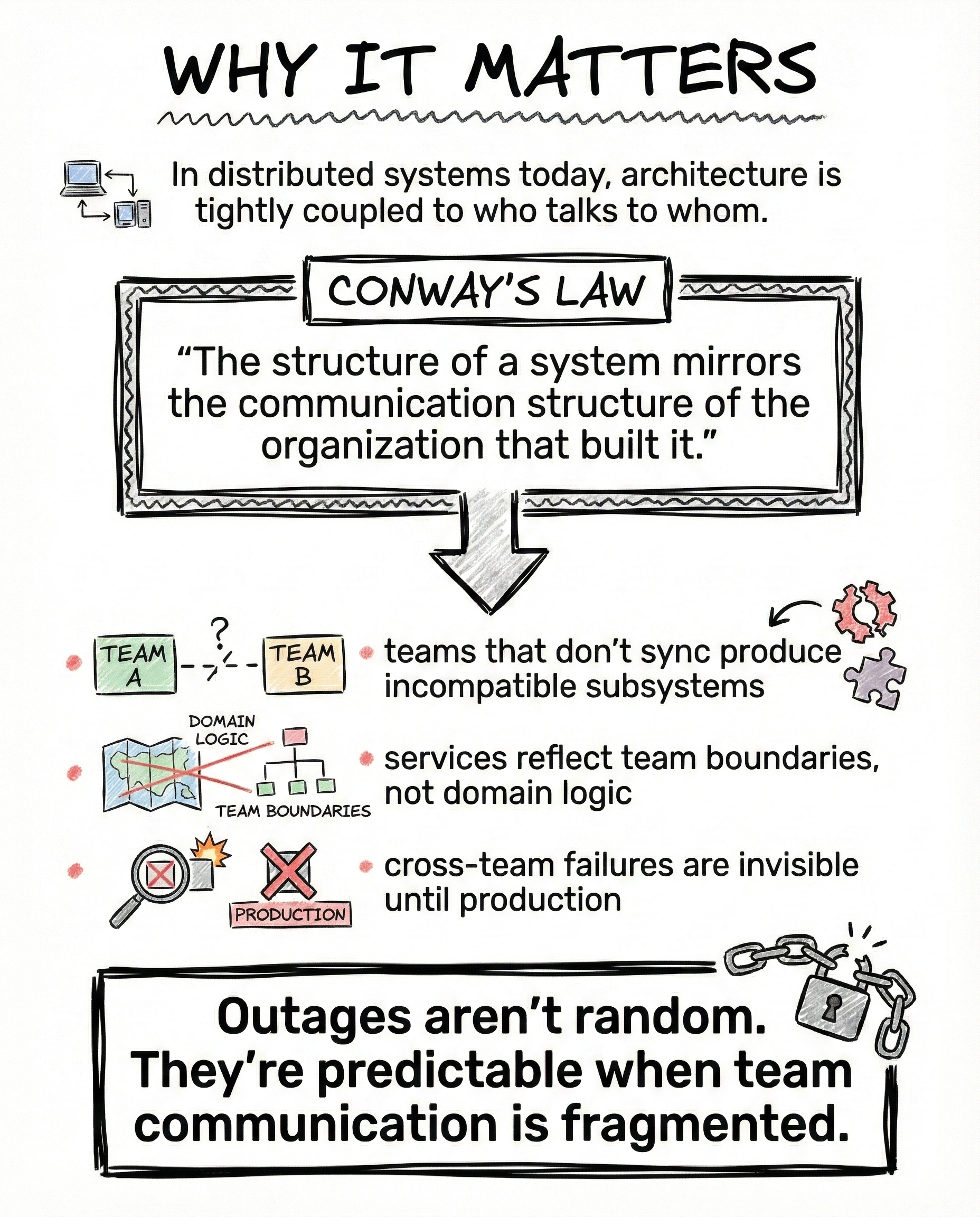
Conway’s Law states that systems mirror the communication structure of the organizations that build them.
What this means in practice:
- teams that do not sync produce incompatible subsystems
- services reflect team boundaries, not domain logic
- cross-team failures stay invisible until production
This is why postmortems often say “unexpected interaction” instead of “bug”.
The interaction was always there.
No one owned it.
How organizational failure shows up in systems
Once systems grow beyond a few engineers, these patterns emerge fast.
Unclear ownership
- multiple teams touch the same service
- nobody owns the full execution path
- issues bounce between teams
Implicit assumptions
- “That team handles X” becomes “no one considered Y”
- assumptions live in heads, not documentation
- failures happen at the seams
Communication gaps
- decoupled teams build loosely related services
- behavior emerges from misaligned intent
- debugging becomes archaeology
This is not academic theory.
This is what every large outage looks like up close.
Real-world mechanisms that cause outages
These failures are organizational, not technical.
Common patterns:
- service boundaries without clear API contracts
- interfaces shipped without versioning discipline
- shared libraries with no ownership guardrails
- multiple squads changing core code independently
- escalation paths that lead to email instead of action
When traffic spikes, these weaknesses collapse instantly.
The system did not fail.
The org did.

Architecture starts with team design
Getting architecture right is not about microservices, monoliths, or APIs.
It is about how teams interact.
Strong systems apply the inverse approach:
design teams to match the architecture you want, not the other way around.
What this looks like in practice:
- one team owns one bounded context
- clear asynchronous contracts between teams
- ownership includes code, infrastructure, runbooks, and alerts
When teams are autonomous, failures localize.
They do not cascade.
What real outages teach you
From incidents I have seen repeatedly:
- a service that fails silently almost always maps to a communication gap
- the hardest bugs live where responsibility was assumed, not assigned
- teams aligned around business domains recover faster than tech-siloed teams
Engineering problems are usually organizational problems wearing a technical mask.
Fix the org design first.
The stack becomes manageable almost automatically.
The real takeaway
You cannot out-architect broken communication.
If the org is fragmented, the system will be too.
If ownership is unclear, reliability will be fragile.
Outages are rarely surprises.
They are delayed consequences.

Closing
This post is part of InsideTheStack, focused on deep engineering truths rooted in real incidents, not slide decks.
Follow along for more.
#InsideTheStack #ConwaysLaw #OrgDesign #SystemArchitecture