Using Sentry & Grafana For Stability
The two tools that tell you when your system is dying
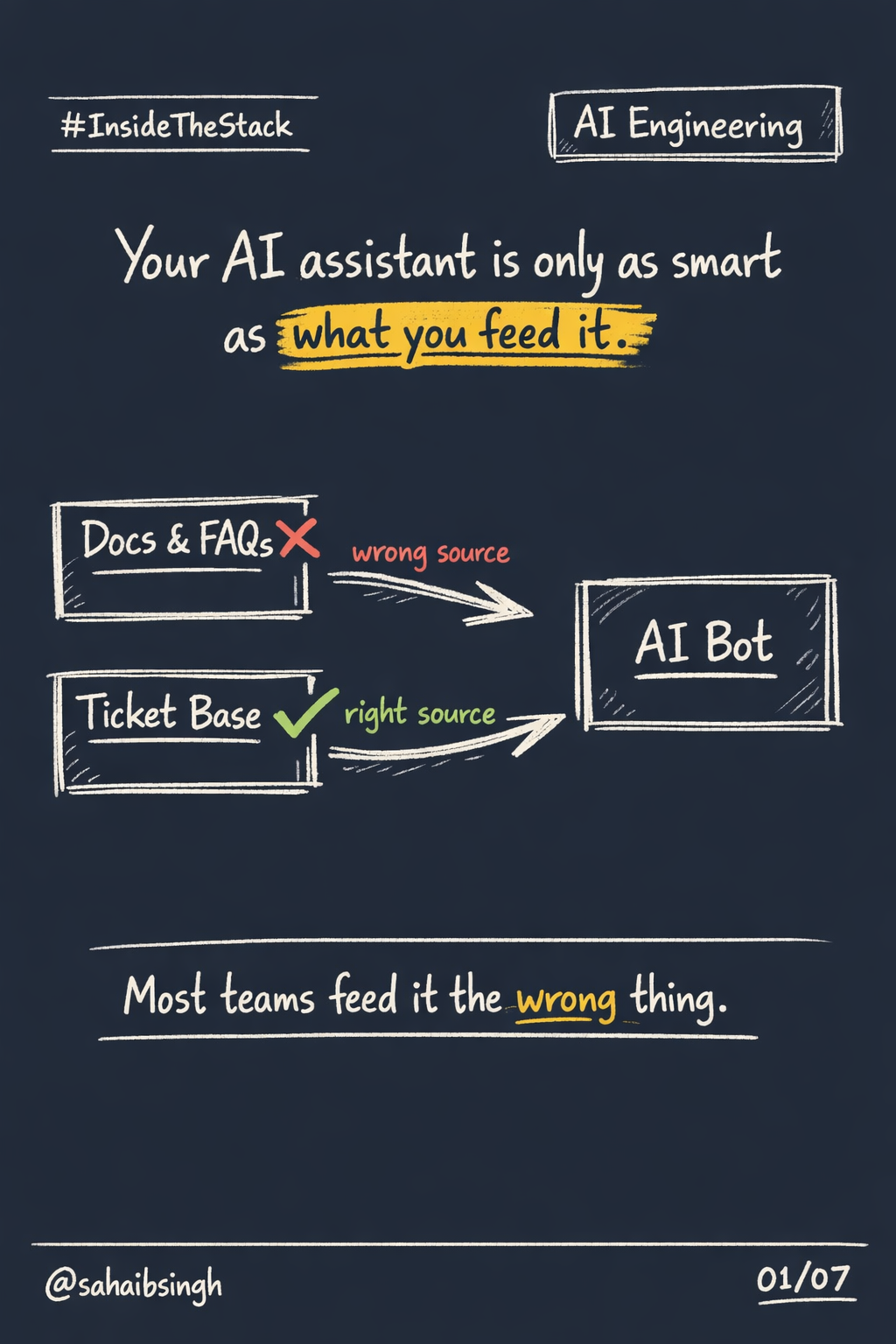
Most systems do not fail suddenly.
They degrade quietly.
Latency creeps up.
Errors spike occasionally.
Memory usage slowly climbs.
By the time users complain, the system has been unhealthy for a while.
Sentry and Grafana exist to catch that phase.
Why observability actually matters
Without proper observability, you are blind to:
- performance degradation
- memory leaks
- latency spikes
- user-side errors
- internal failures
Monitoring is not about dashboards.
It is about early warnings.
Good tools do not just show problems.
They warn you before those problems turn into outages.

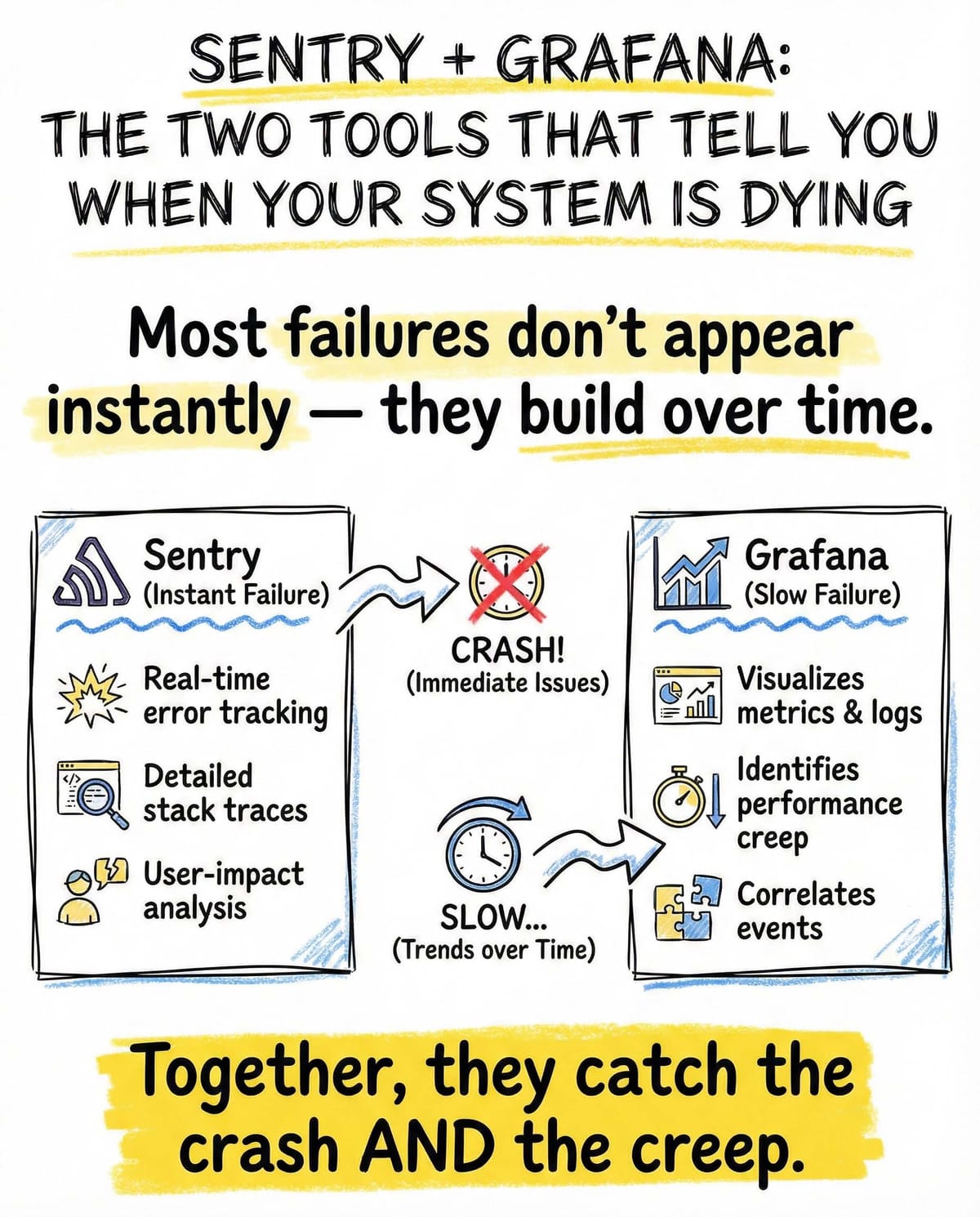
What each tool is really good at
Sentry
Sentry is about application-level truth.
It gives you:
- intelligent error grouping
- release-level visibility
- breadcrumb tracing of user actions
- ownership and accountability
Sentry answers one question clearly:
What is breaking for users right now and why?
Grafana
Grafana is about system-level health.
It gives you:
- real-time dashboards
- alerting on metrics
- custom signals
- infrastructure visibility
Grafana answers a different question:
Is the system itself behaving normally?
Together, they give you application and infrastructure visibility.
You need both.
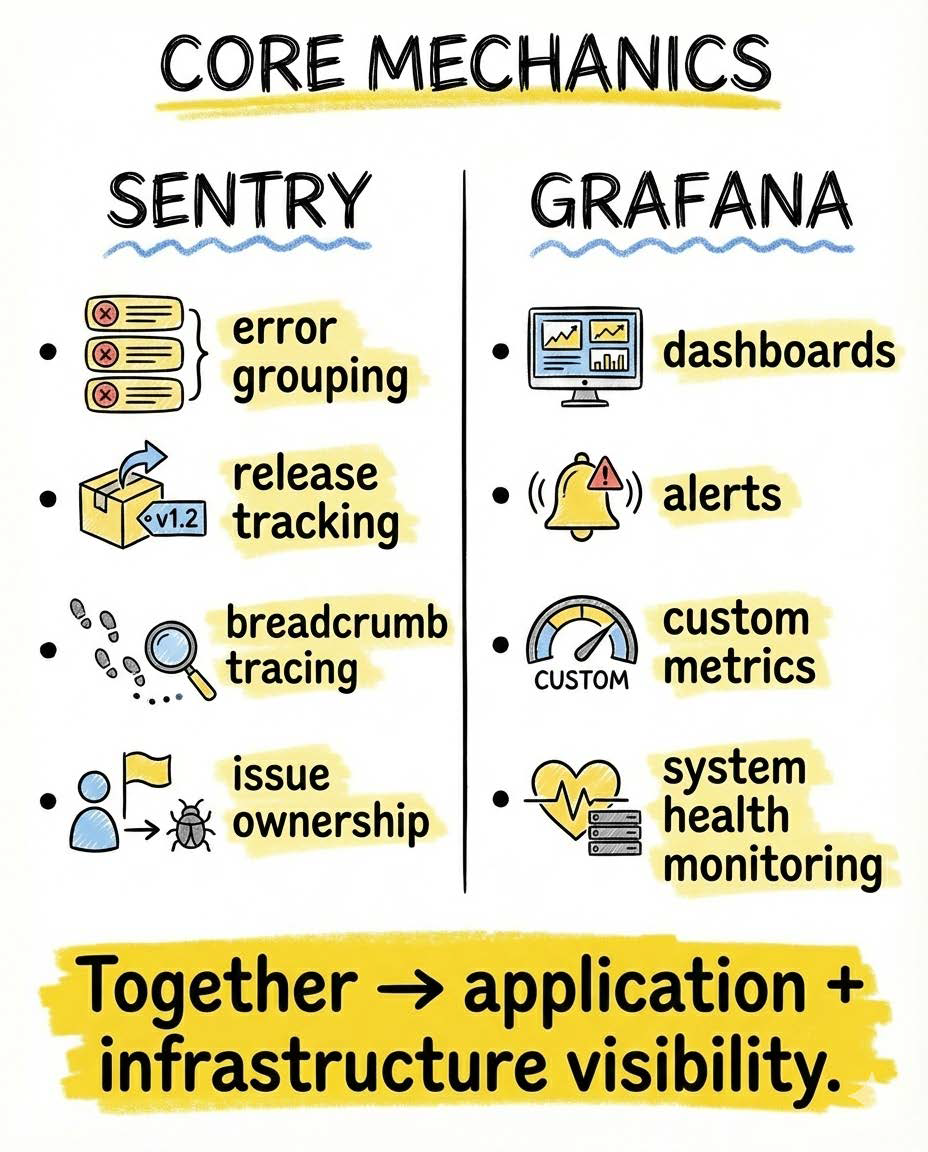
What real monitoring looks like
In practice, meaningful monitoring focuses on:
- p95 and p99 latency, not averages
- error rate thresholds
- sudden API usage spikes
- memory consumption trends
- CPU saturation
- rate limiting behavior
When you catch patterns early, outages never happen.
They get prevented.
That is the real goal.
Lessons I learned the hard way
These rules shaped how I monitor systems now:
- never trust a system you cannot observe
- logs tell stories dashboards never will
- alerts should map to user impact, not noise
- dashboards should be simple and actionable
- do not over-monitor, monitor what matters
More charts do not mean more clarity.
Better signals do.
The real takeaway
Observability is not optional infrastructure.
It is a design choice.
Systems that are observable age well.
Systems that are not eventually surprise you at the worst time.
You cannot fix what you cannot see.

Closing
This post is part of InsideTheStack, where the focus is practical engineering habits that keep systems stable under real usage.
If you want more of this thinking, you can find me on LinkedIn:
https://www.linkedin.com/in/sahaibsingh/
Follow along for more.
#InsideTheStack #Sentry #Grafana #Monitoring